2025
VeriCoder: Enhancing LLM-Based RTL Code Generation through Functional Correctness Validation
Anjiang Wei, Huanmi Tan, Tarun Suresh, Daniel Mendoza, Thiago SFX Teixeira, Ke Wang, Caroline Trippel, Alex Aiken
NuerIPS 2025 Fourth Workshop on Deep Learning for Code 2025
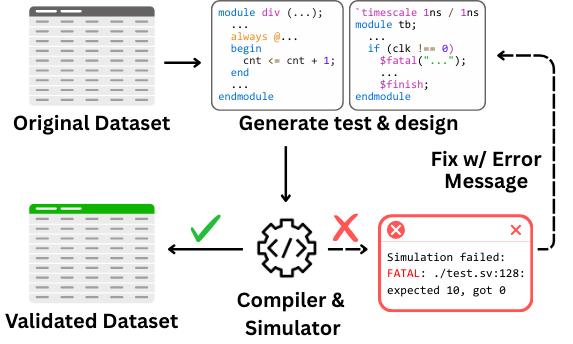
VeriCoder is a model for RTL (Register Transfer Level) code generation, fine-tuned on a novel dataset that is functionally validated via feedback-directed refinement. Unlike prior datasets that only ensure syntactic correctness, our dataset guarantees that each RTL design passes automatically generated unit tests aligned with its natural language specification. Our key contributions include: (1) a large-scale dataset of 125,000+ examples with simulation-passing RTL designs, (2) a feedback-driven construction methodology that iteratively refines designs and tests based on test results, (3) superior performance with up to +71.7% relative improvement on VerilogEval benchmarks, and (4) comprehensive resources including dataset, model weights, inference scripts, and training pipeline.
VeriCoder: Enhancing LLM-Based RTL Code Generation through Functional Correctness Validation
Anjiang Wei, Huanmi Tan, Tarun Suresh, Daniel Mendoza, Thiago SFX Teixeira, Ke Wang, Caroline Trippel, Alex Aiken
NuerIPS 2025 Fourth Workshop on Deep Learning for Code 2025
VeriCoder is a model for RTL (Register Transfer Level) code generation, fine-tuned on a novel dataset that is functionally validated via feedback-directed refinement. Unlike prior datasets that only ensure syntactic correctness, our dataset guarantees that each RTL design passes automatically generated unit tests aligned with its natural language specification. Our key contributions include: (1) a large-scale dataset of 125,000+ examples with simulation-passing RTL designs, (2) a feedback-driven construction methodology that iteratively refines designs and tests based on test results, (3) superior performance with up to +71.7% relative improvement on VerilogEval benchmarks, and (4) comprehensive resources including dataset, model weights, inference scripts, and training pipeline.
SATBench: Benchmarking LLMs’ Logical Reasoning via Automated Puzzle Generation from SAT Formulas
Anjiang Wei, Yuheng Wu, Yingjia Wan, Tarun Suresh, Huanmi Tan, Zhanke Zhou, Sanmi Koyejo, Ke Wang, Alex Aiken
EMNLP Main 2025
We introduce SATBench, a benchmark for evaluating the logical reasoning capabilities of large language models (LLMs) through logical puzzles derived from Boolean satisfiability (SAT) problems. Unlike prior work that focuses on inference rule-based reasoning, which often involves deducing conclusions from a set of premises, our approach leverages the search-based nature of SAT problems, where the objective is to find a solution that fulfills a specified set of logical constraints. Each instance in SATBench is generated from a SAT formula, then translated into a story context and conditions using LLMs. The generation process is fully automated and allows for adjustable difficulty by varying the number of clauses. All 2100 puzzles are validated through both LLM-assisted and solver-based consistency checks, with human validation on a subset. Experimental results show that even the strongest model, o4-mini, achieves only 65.0% accuracy on hard UNSAT problems, close to the random baseline of 50%. SATBench exposes fundamental limitations in the search-based logical reasoning abilities of current LLMs and provides a scalable testbed for future research in logical reasoning.
SATBench: Benchmarking LLMs’ Logical Reasoning via Automated Puzzle Generation from SAT Formulas
Anjiang Wei, Yuheng Wu, Yingjia Wan, Tarun Suresh, Huanmi Tan, Zhanke Zhou, Sanmi Koyejo, Ke Wang, Alex Aiken
EMNLP Main 2025
We introduce SATBench, a benchmark for evaluating the logical reasoning capabilities of large language models (LLMs) through logical puzzles derived from Boolean satisfiability (SAT) problems. Unlike prior work that focuses on inference rule-based reasoning, which often involves deducing conclusions from a set of premises, our approach leverages the search-based nature of SAT problems, where the objective is to find a solution that fulfills a specified set of logical constraints. Each instance in SATBench is generated from a SAT formula, then translated into a story context and conditions using LLMs. The generation process is fully automated and allows for adjustable difficulty by varying the number of clauses. All 2100 puzzles are validated through both LLM-assisted and solver-based consistency checks, with human validation on a subset. Experimental results show that even the strongest model, o4-mini, achieves only 65.0% accuracy on hard UNSAT problems, close to the random baseline of 50%. SATBench exposes fundamental limitations in the search-based logical reasoning abilities of current LLMs and provides a scalable testbed for future research in logical reasoning.
Improving Assembly Code Performance with Large Language Models via Reinforcement Learning
Anjiang Wei, Tarun Suresh, Huanmi Tan, Yinglun Xu, Gagandeep Singh, Ke Wang, Alex Aiken
NeurIPS 2025 Fourth Workshop on Deep Learning for Code 2025
Large language models (LLMs) have demonstrated strong performance across a wide range of programming tasks, yet their potential for code optimization remains underexplored. This work investigates whether LLMs can optimize the performance of assembly code, where fine-grained control over execution enables improvements that are difficult to express in high-level languages. We present a reinforcement learning framework that trains LLMs using Proximal Policy Optimization (PPO), guided by a reward function that considers both functional correctness, validated through test cases, and execution performance relative to the industry-standard compiler gcc -O3. To support this study, we introduce a benchmark of 8,072 real-world programs. Our model, Qwen2.5-Coder-7B-PPO, achieves 96.0% test pass rates and an average speedup of 1.47x over the gcc -O3 baseline, outperforming all 20 other models evaluated, including Claude-3.7-sonnet. These results indicate that reinforcement learning can unlock the potential of LLMs to serve as effective optimizers for assembly code performance.
Improving Assembly Code Performance with Large Language Models via Reinforcement Learning
Anjiang Wei, Tarun Suresh, Huanmi Tan, Yinglun Xu, Gagandeep Singh, Ke Wang, Alex Aiken
NeurIPS 2025 Fourth Workshop on Deep Learning for Code 2025
Large language models (LLMs) have demonstrated strong performance across a wide range of programming tasks, yet their potential for code optimization remains underexplored. This work investigates whether LLMs can optimize the performance of assembly code, where fine-grained control over execution enables improvements that are difficult to express in high-level languages. We present a reinforcement learning framework that trains LLMs using Proximal Policy Optimization (PPO), guided by a reward function that considers both functional correctness, validated through test cases, and execution performance relative to the industry-standard compiler gcc -O3. To support this study, we introduce a benchmark of 8,072 real-world programs. Our model, Qwen2.5-Coder-7B-PPO, achieves 96.0% test pass rates and an average speedup of 1.47x over the gcc -O3 baseline, outperforming all 20 other models evaluated, including Claude-3.7-sonnet. These results indicate that reinforcement learning can unlock the potential of LLMs to serve as effective optimizers for assembly code performance.
2024

Convallis a cras semper auctor neque vitae rutrum quisque non tellus orci ac
Your Name, James Wang, Some Other Name, John Doe
International Conference on Machine Learning (ICML) 2024 Spotlight
Photo by Pineapple Supply Co. on Unsplash. Please put a tldr (too-long-didnt-read, 1~2 sentences) of your publication here. It is not recommended to put the actual abstract here because it is usually too long to fit in. $\LaTeX$ is supported. $a=b+c$.
Convallis a cras semper auctor neque vitae rutrum quisque non tellus orci ac
Your Name, James Wang, Some Other Name, John Doe
International Conference on Machine Learning (ICML) 2024 Spotlight
Photo by Pineapple Supply Co. on Unsplash. Please put a tldr (too-long-didnt-read, 1~2 sentences) of your publication here. It is not recommended to put the actual abstract here because it is usually too long to fit in. $\LaTeX$ is supported. $a=b+c$.